Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

Pythonにおける特殊記号の「¥」記号(バックスラッシュ)とエスケープシーケンスの基本について解説
今回はPythonだけに限らず、プログラミング全般というか、そもそもPCのキーボード操作にも関わるネタで、Pythonの特殊文字「¥」記号(マーク)の取り扱いについての解説です。
Contents
まず次の画像を見て下さい。普通にみなさんが使っている日本語用キーボードには画像中AとBの2種類のキーがあると思います。
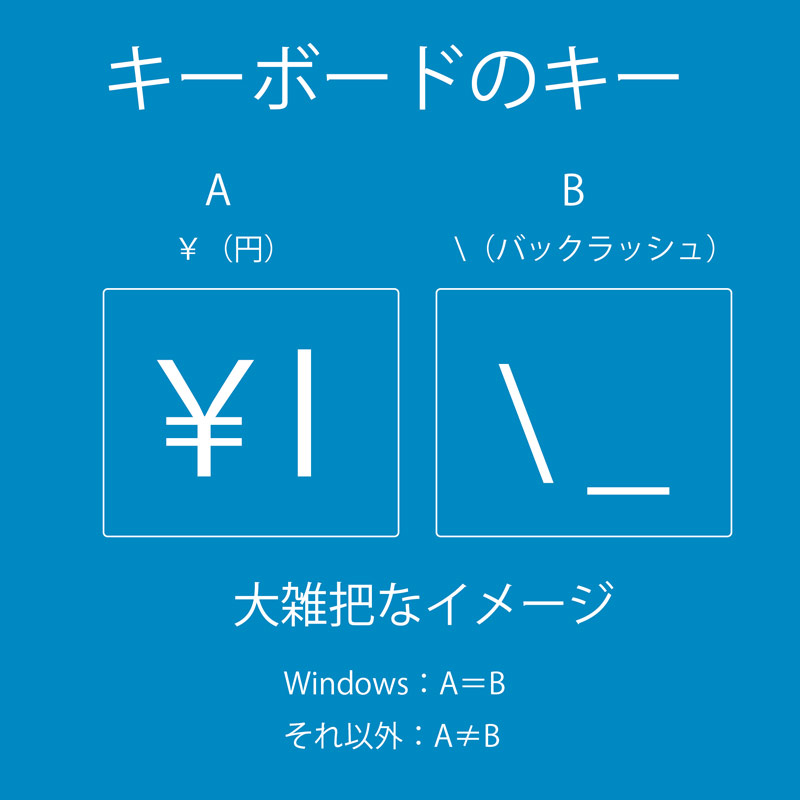
だいたいのキーボードだとAが右上のほう(エンターキーの上部)、Bが右下のほうに位置していると思います。そして、わざわざキーボードにこのように2種類のキーがあるのですから基本的に
は別扱いです。特にUnicode(ユニコード)と言われる国際的文字規格ではそうなっています。
ですが、大ざっぱにいうと、Windowsについては昔から「PC内部での処理は、円記号をバックスラッシュへ変換する」という仕組みを採用しています。つまり「コンピュータ内部では円記号=バックスラッシュ」となっています。内部では。一方でWindowsの場合は人間が見る画面上は「¥」です。
この点、エディタのVisual Studio Codeの画面で見てみましょう。次の画像を見て下さい。
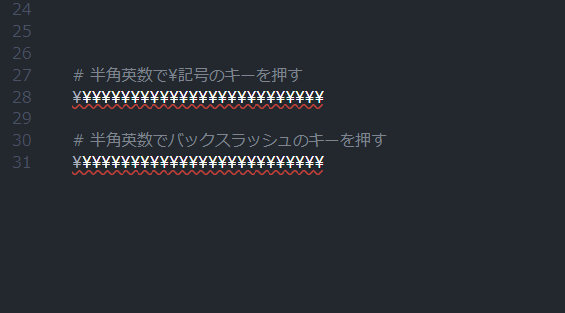
これはWindowsのVS CodeでPythonファイルを開いて、半角英数モードで¥キーとバックスラッシュのキーをそれぞれ叩いて入力した場合の画面です。どちらも¥だけになっていますね。
バッスクラッシュ「\」キーを叩いて入力したのに、表示上は「¥」になっています。
Windowsは、バックスラッシュ「\」キーを叩いたときに、表示だけ「¥」にしていますが、内部ではやはりバックスラッシュとして処理しています。
また上述のように、Windowsでは「¥」キーを叩いて「¥」を入力してもすべてバックスラッシュへ変換されますので、実は「¥」キーを押して「¥」を入力したと思っても、内部ではバックスラッシュを入力したことなっているため、実質的には「¥」を入力できていないと言っていいかもしれません。
よってWindows日本語入力のもとでは、「見た目上はバックスラッシュの入力ができない」ということになっていますが、実際は「¥を入力できない」ということになります。
それに対して、Macでは¥とバックスラッシュは見た目上も内部処理上も明確に区別されています。¥記号は見た目も実際も¥記号であり、バックラスッシュは見た目も実際もバックスラッシュです。なお、Macのキーボードでバックスラッシュを入力するには、
「optionキー」 + 「¥記号キー」とします。
この結果、Windows上で「¥」を入力したとしても、それは実際にはバックスラッシュであるため、そのファイルをMacで開くと、Macは「これはバックスラッシュだ」と解釈し、見た目上もバックスラッシュが表示されます。Windowsで「¥」でも、Windows以外だと「バックスラッシュ」として表示されます。
ただこうした入力システム・文字システムの違いは使うフォントや文字規格などによっていろいろ左右されるため、いちがいにOSがどうこうだからとは言えない場合もあります。
そして、このバックスラッシュ「\」としての¥記号は、プログラミングのうえで特別な機能を持つことが多いです。それはエスケープシーケンスという機能です。wikipedia「エスケープシーケンス」では次のように説明されています。
エスケープシーケンス (escape sequence) とは、コンピュータシステムにおいて、通常の文字列では表せない特殊な文字や機能を、規定された特別な文字の並びにより表したもの。
wikipedia「エスケープシーケンス」
代表的なものに、C言語の文字列リテラル中でバックスラッシュ(\、U+005C)で始めることで改行コードなどを表現するものや、エスケープコード (U+001B, ESC) で始めるISO/IEC 2022 (JIS X 0202) における文字集合の指示・呼び出しのシーケンス(漢字シフトコードも参照)や、ISO/IEC 6429 (ECMA-48、JIS X 0211) の画面制御シーケンス(いわゆる「ANSIエスケープシーケンス(英語版)」)がある。
wikipedia「エスケープシーケンス」
ここで、バックスラッシュについての記述がありますね。C言語(C#言語)についてのマイクロソフト社の公式解説ページでも、
円記号 (\) の後に文字が続く、または数字の組み合わせで構成される文字の組み合わせは、”エスケープ シーケンス” と呼ばれます。
エスケープ シーケンス
との記載があり、バックスラッシュ「\」について特殊な役割があることが示されています。
たとえば、Pythonのコードで、
print("Tom's shoes") # ダブルクオテーションの中にシングルクオテーションの場合とすると、問題なく文字列Tom’s shoesと表示されます。
しかし、
print('Tom's shoes') # シングルクオテーションの中にシングルクオテーションの場合このように、シングルクオテーションの中でさらにシングルクオテーションを使うと文法エラー(SyntaxError)となります。
これを回避するために、エスケープシーケンスを使ってみます。バックスラッシュ「\」を用いて以下のようにします。
print('Tom\'s shoes') # エスケープシーケンスを使うこのようにすると、文字列Tom’s shoesと表示できます。
このバックスラッシュはまさにエスケープシーケンスの1つです。不都合を回避するための特別な文字と言えるでしょう。
では、以下の項目でPythonにおけるバックスラッシュ「\」(または¥記号)についてのエスケープシーケンスを見ていきましょう。
公式ドキュメントでは次のようにPythonで認識されるエスケープシーケンスが示されています。
| エスケープシーケンス | 意味 |
|---|---|
\newline | バックスラッシュと改行文字が無視されます |
\\ | バックスラッシュ (\) |
\' | 一重引用符 (') |
\" | 二重引用符 (") |
\a | ASCII 端末ベル (BEL) |
\b | ASCII バックスペース (BS) |
\f | ASCII フォームフィード (FF) |
\n | ASCII 行送り (LF) |
\r | ASCII 復帰 (CR) |
\t | ASCII 水平タブ (TAB) |
\v | ASCII 垂直タブ (VT) |
\ooo | 8 進数値 ooo を持つ文字 |
\xhh | 16 進数値 hh を持つ文字 |
では上表の項目について、上から順番にそれぞれPythonでどのような結果になるのか確かめてみましょう。結果は次表のようになります。(一般的なWindows日本語環境で、日本語フォントを使用したエディアVS Codeでの結果となります。Windows以外では¥記号をバックスラッシュへ置き換えて考えてください)
| 文字列 | print(“文字列”)の結果 |
|---|---|
| Tom¥ Mary (¥の後に改行してMary) | TomMary(改行も¥も無視される) |
| ¥¥ | ¥ |
| /¥’ | ‘ (例:”Tom\’s shoes”→”Tom’s shoes”) |
| ¥” | “ |
| ¥a | (何も表示されない。ASCII 端末ベル (BEL)だから:上表参照) |
| Tom¥bMary | ToMary (¥bはバックスペースなので、直前のmが削除されている) |
| Tom¥fMary¥fTom | Tom Mary Tom |
| Tom¥nMary¥nTom | Tom Mary Tom |
| Tom¥rMary | Mary |
| Tom¥tMary | Tom Mary |
| Tom¥vMary | Tom Mary |
| Tom¥115¥141¥162¥171 | TomMary (8進数で115はM、141はa、162はr、171はy) |
| Tom¥x4D¥x61¥x72¥x79 | TomMary (16進数で4DはM、61はa、72はr、79はy) |
以上のようになります。環境によって多少見え方は異なるかもしれませんが、だいたい同じようなものでしょう。何かの参考になれば幸いです。