Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Pandasで複数の特定の列の情報だけを取得・表示させる方法の解説
今回はPythonでPandasを使ったデータ分析の基礎として、Pandasで特定の列を選んで表示させる方法の解説です。これができるだけで、かなりデータが見やすくなるのでぜひ練習してみてください。といってもとても簡単です。
今回の記事で作業する環境は、Visual Studio Code上でJupyter Notebookを動かすものでDockerを使った環境です。使用するデータなども含めてその作業環境の構築方法などについては次の記事を御覧ください。
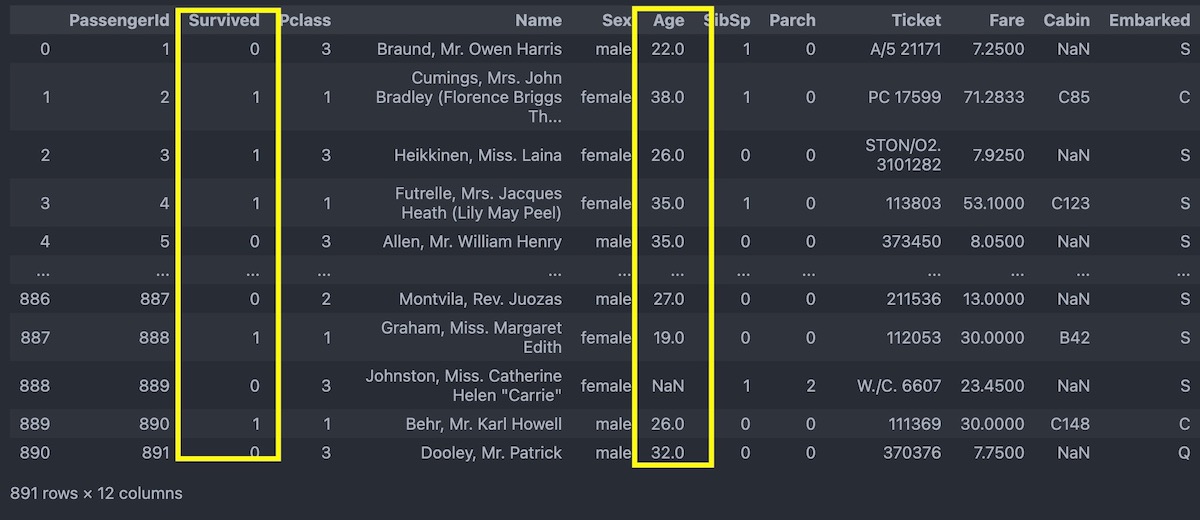
Pandasで特定の列の情報だけを表示させるには以下の2つの方法があります。今回は次のような表(データフレーム)を例にして解説します。このデータフレームでの列ラベルとは、「PassengeerID」とか「Survived」「Pclass」などのことです。
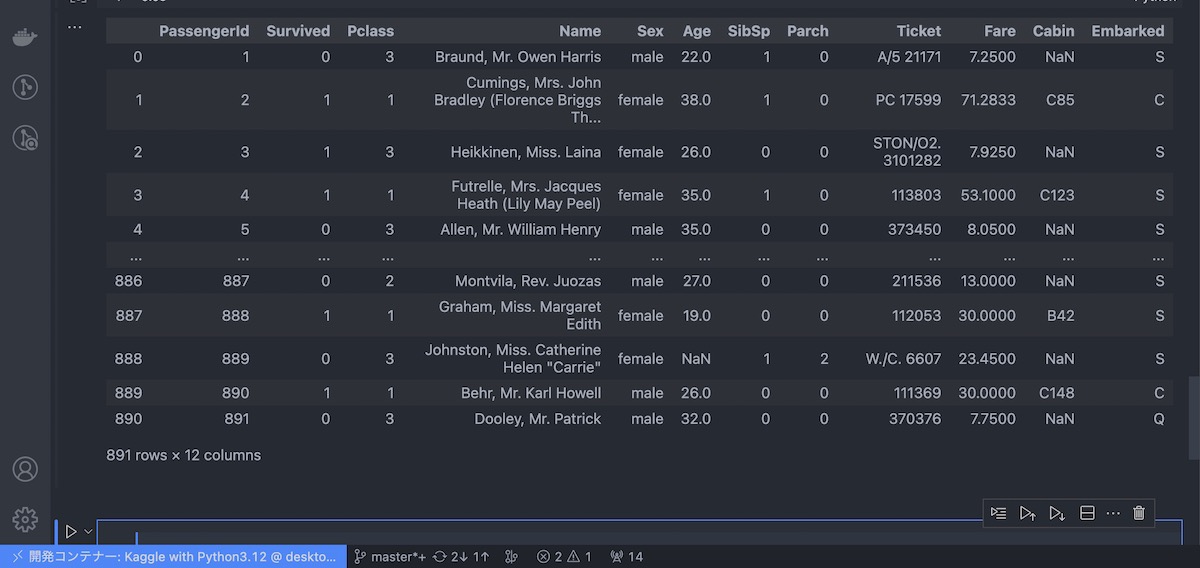
まず1つの列だけを表示させてみましょう。今回は次のようにAgeという列ラベルのついた列だけを表示させます。
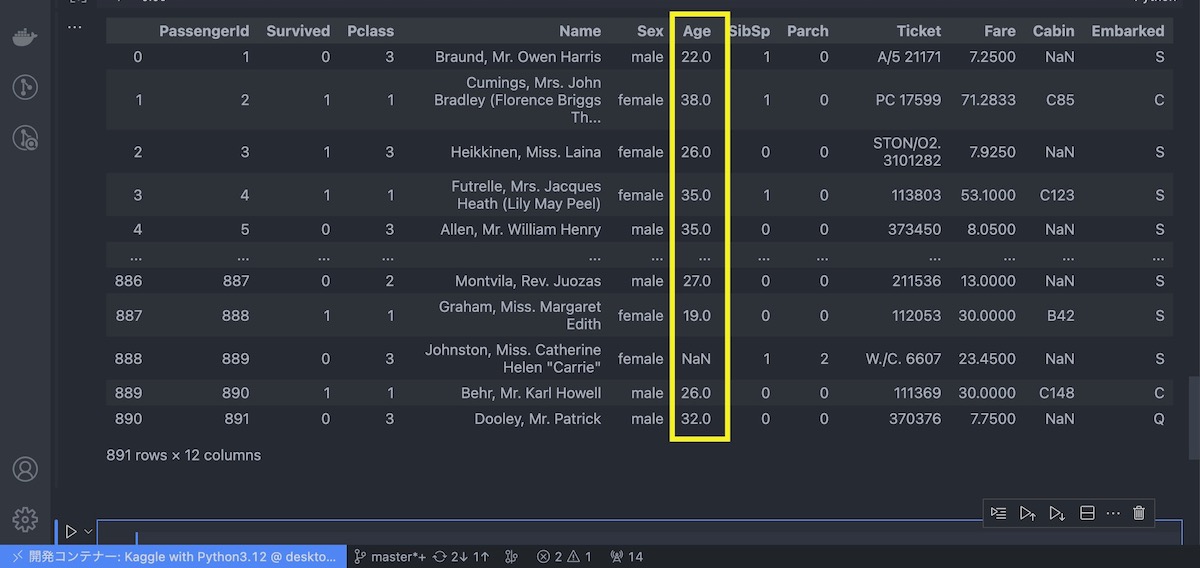
この場合は次ように入力します。
pandas.データフレーム['列ラベルの名称']たとえば、今回ならば次のようにします。
import pandas as pd
(略)
train_df = pd.read_csv(略)
train_df["Age"]この実行結果はこうなります。
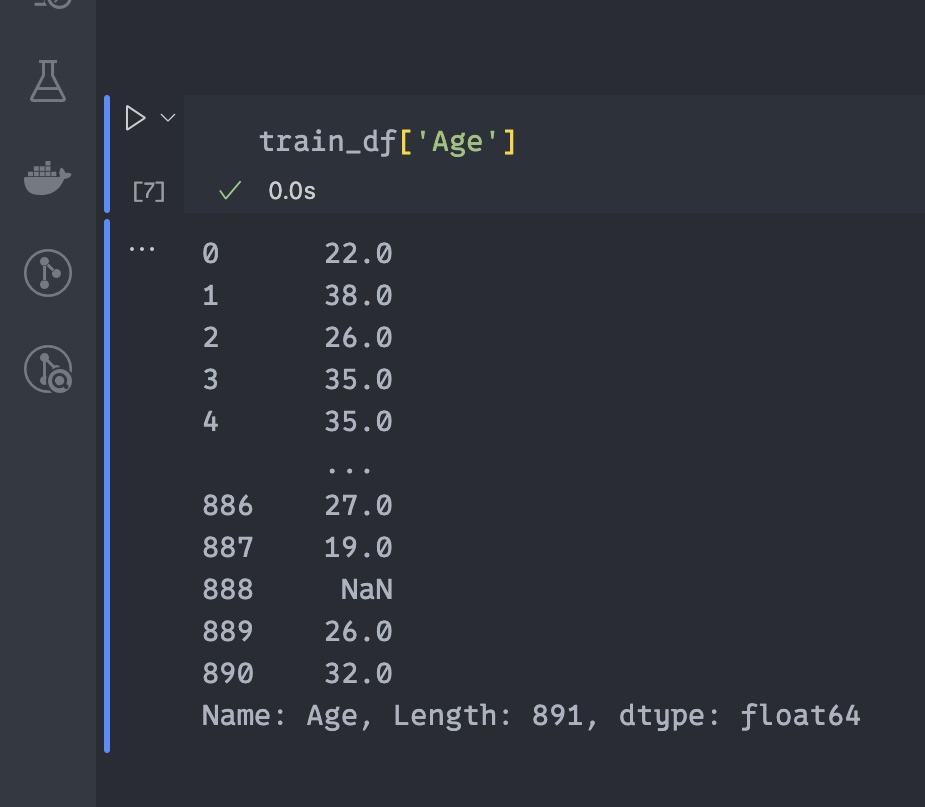
上のデータフレーム全体の画像と見比べてもらうとわかるように、きちんとAgeという列の情報だけが取得・表示できています。
なお、このように1列だけの情報を取得したときそのオブジェクトの型を調べると、
type(train_df['Age'])その結果は、
<class 'pandas.core.series.Series'>このように、DataFrame型ではなくSeriesという型になります。
次に複数の列ラベルの情報を取得・表示させてみましょう。
たとえば、上画像のようにAgeとSurvivedという2つの列の情報だけを抽出したい場合は、
pandas.データフレーム[["列ラベル名1", "列ラベル名2"]]このように指定します。実際に次のように入力して、
train_df[["Age", "Survived"]]実行すると、結果は次のとおりです。
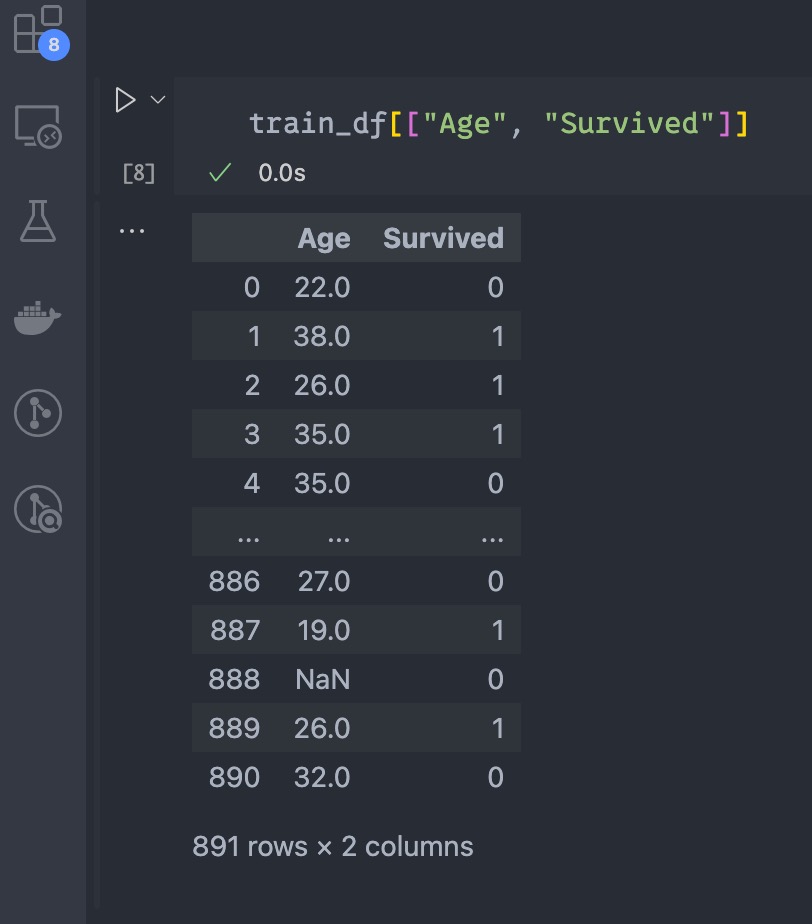
上の1列の情報だけを取得した場合と同様に、このようにして複数列の情報を取得したオブジェクトについても型を調べてみましょう。
type(train_df[['Age', 'Survived']])eそうすると今回は、
<class 'pandas.core.frame.DataFrame'>このようにDataFrame型となりました。
以上のような方法だけでなく、もう1つの方法として「pandas.DataFrame.loc」を使う方法があります。
Pandas公式サイト:pandas.DataFrame.loc
使い方はいろいろあるのですが、今回は「行について」のスライス表記と組み合わせて使う方法を紹介します。この場合の基本的な使い方は次のとおりです。
pandas.データフレーム.loc[行の始点インデックス:行の終点インデックス, [列ラベルの指定]]たとえば、この画像のようにAgeとSurvivedの列だけをその各列の最初から最後まで表示させるならば、次のように指定します。
train_df.loc[:, ['Age', 'Survived']]ここでは、
| 行についてのスライス | 始点のインデックス:指定なし 終点のインデックス:指定なし |
| 列ラベルの指定 | AgeとSurvivedという2つ列を指定 |
このように指定しています。行についてのスライスは始点も終点も指定していないため、各列の最初から最後までのデータがすべて表示されることになります。
こうしてもこのように、上の場合と同じ結果となります、
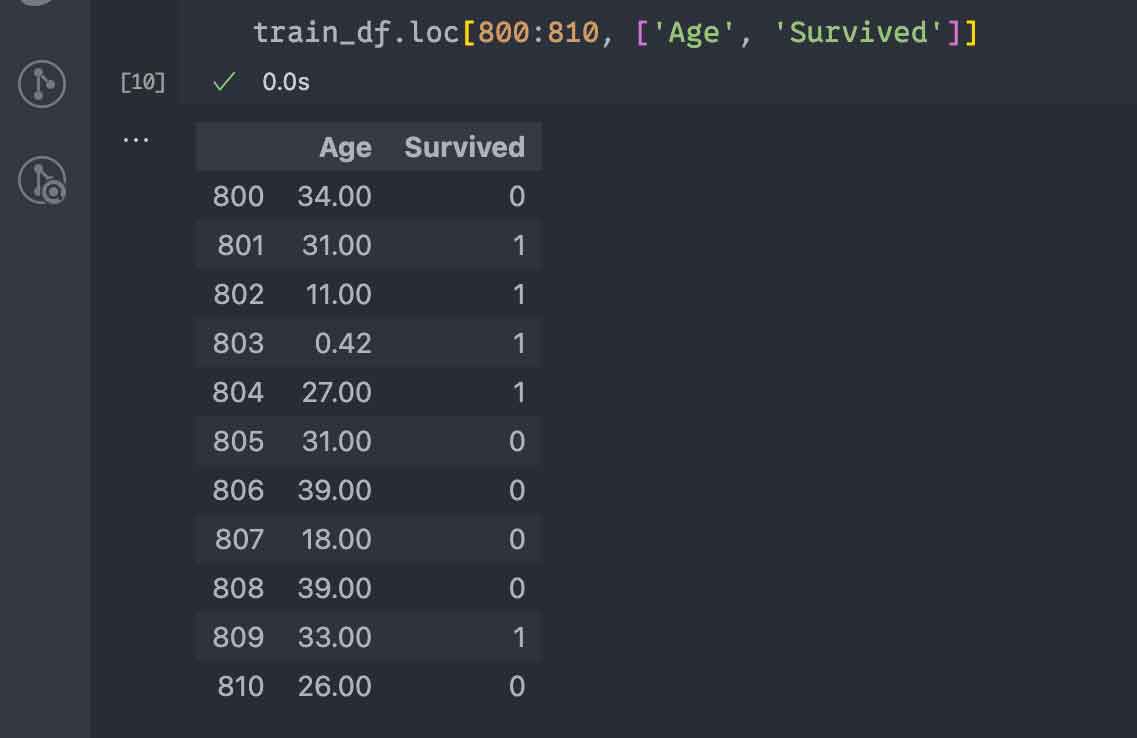
またたとえば、行インデックスも指定して、
train_df.loc[800:810, ['Age', 'Survived']]このようにすれば、次の画像のようにAgeとSurvivedの行800〜810までを抽出できます。