Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
【初心者向け】Pandasのiloc/locを使って特定の行/列を抽出・表示させる方法の解説
今回はPandasで特定の行や列の情報だけを選んで抽出したい・表示したいときに使えるilocとlocの使い方の基本を解説します。データ分析でよく使われる機能ですので慣れておくと今後の学習などが捗ります。
Contents
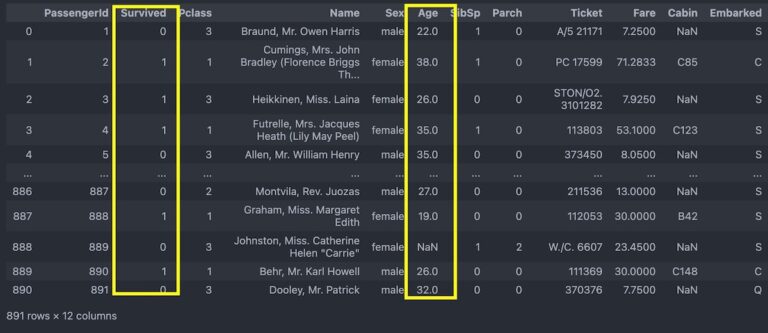
今回は次のようなPandaのデータフレームの表を使って解説します。データサイエンスコンペティションKaggleのタイタニックのデータです。
なお、Dockerを使ってWindowsでもMacでもLinuxでも同じPython環境やデータ分析環境を作る方法をこちらの記事で解説しています。
Dockerは初歩的な使い方だけでもできるようになると本当に便利なのでぜひ試してみてください。
ilocとは、行または列のインデックス(Index)情報を基準として特定の行や列だけを抽出する機能です。
Pythonにおけるインデックスについては、リストオブジェクトを例にするのが理解しやすいでしょう。まずリストオブジェクトを1つ作ってみます。
new_list: list = ["Google", "Apple", "Microsoft"]このリストにおいてインデックスとは、要素の順番を示す整数です。ここでは次のように順番と要素が対応しています。
| インデックス (標準では0から始まる) | 要素 |
|---|---|
| 0 | |
| 1 | Apple |
| 2 | Microsoft |
最初のインデックスは、標準では0から始まることに注意しましょう。
では実際にインデックスを指定してリストの各要素を確かめてみましょう。
new_list[0]
new_list[1]
new_list[2]結果は、
>>> new_list[0]
'Google'
>>> new_list[1]
'Apple'
>>> new_list[2]
'Microsoft'となります。Micorsoftは3番目の要素ですが、インデックス番号は2となるので注意しましょう、
ilocは基本的に次のように使います。
データフレーム.iloc[①, ②]この①と②は、
| ① | 行のインデックス情報 |
| ② | 列のインデックス情報 |
このような情報となります。
②の列のインデックス情報は省略が可能です。しかし、行のインデックス情報を省略して、
データフレーム.iloc[列のインデックス情報]と書いても、頭の中で思い描いた「列のインデックス情報」の指定は実際には「行のインデックス情報」の指定として扱われます。なぜならば、最初に書いてあるインデックス情報はつねに「行のインデックス情報」となるように設計されているからです。
上述のように今回はこのようなデータフレームを使います。このデータフレームオブジェクトの名前を今回は「train_df」としています。
ではこのデータフレームのうち、行インデックスの0番から4番までの5つのデータを抽出してみます。Pythonにおけるスライス表記([X:Y]という書き方)を使います。
train_df.iloc[0:5]注意点は、次の2点です。
この結果は、
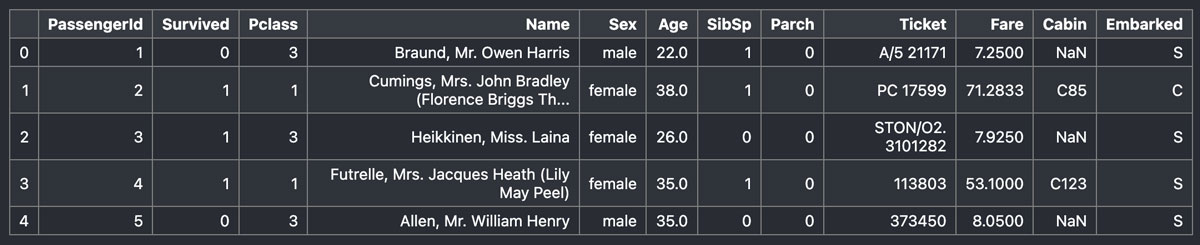
このようになります。
ちなみに同じ結果を実現するために、ilocを使わなくても次のようにheadメソッドを使うこともできます。
train_df.head(5)では次の行と列の両方ともインデックスを指定してみましょう。
まずそもそも列のインデックスというものを把握しておきましょう。そのためにひとまずcolumnsを使い、データフレームの列のラベルを確認しておきましょう。
train_df.columnsこれを実行すると、
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')続いて、
train_df.columns[0]とすると、
'PassengerId'となります。このように列のラベルもインデックス情報を持っていることがわかりました。
などのように対応します。
そこで次のようにすると、
train_df.iloc[0:5, 0:2]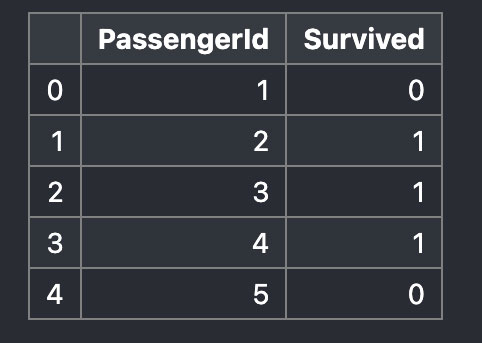
行のインデックス0〜4番までと、列のラベルのインデックス0番である「PassengerId」と、インデックス1番である「Survived」もあわせて抽出することができます。
このilocにおけるインデックスは整数を使って指定しますが、実はPythonの普通のリストと同じく負の整数も使えます。ただ少し癖がある結果となります。
たとえば、
train_df.iloc[-5:-3, 0:2]これはインデックス番号が-5から-4(-3-1 = -4だから)の情報を抽出することとなります。
これの結果は、
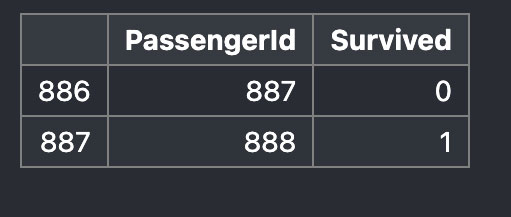
このようになります。
これは行のインデックスが次のようになっているからです。
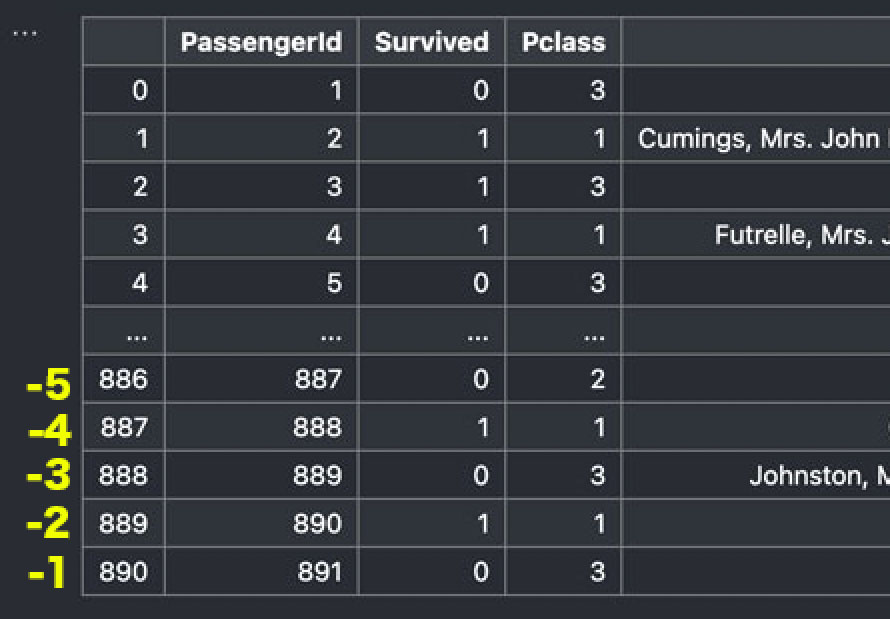
実は、Series型またはDataFrame型を呼び出す関数で、変数が1つだけの関数を指定することもできます。よく使われるのがラムダ関数でしょう。
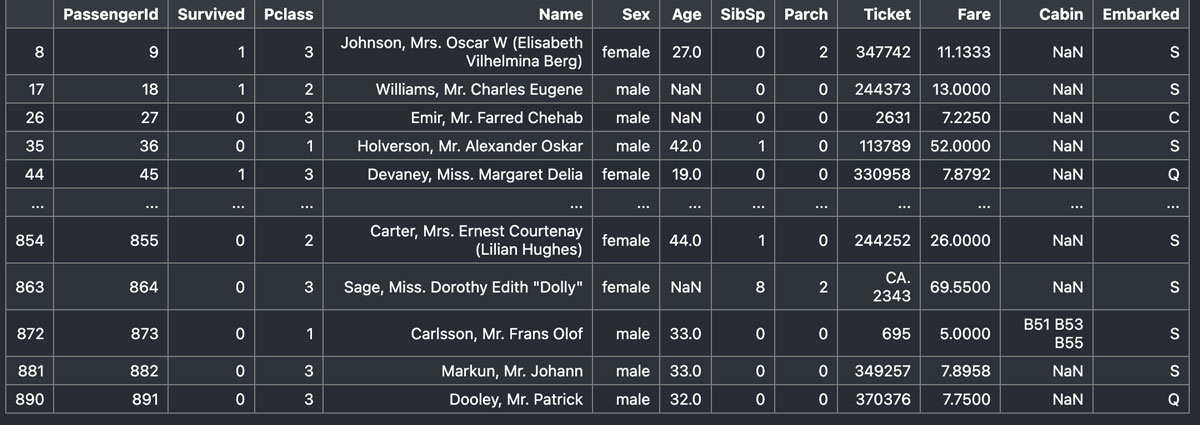
たとえば、行のインデックスについて、「9で割ったときの余りが8となるインデックス番号」だけ抽出したいときは次のようにします。
train_df.iloc[lambda x: x.index % 9 == 8]結果はこうなります。
公式APIリファレンス:pandas.DataFrame.loc
locは、
などによって行や列を指定するものです。
ilocとの違いは、上述の通りilocは「インデックス(index)」情報を使って行や列を指定するものですが、locは「ラベル」を使って指定するものという点が本質的な違いとなるでしょうか。
ですが実は重要な違いがあと1つあります。それはスライス表記を使って範囲を指定した場合の動作が違うことです。この点については下記「使用例2:行と列の両方についてスライスで指定」で解説しています。
ilocと同じく、locも基本的に次のように使います。
データフレーム.loc[①, ②]この①と②は、
| ① | 行のインデックス情報 |
| ② | 列のインデックス情報 |
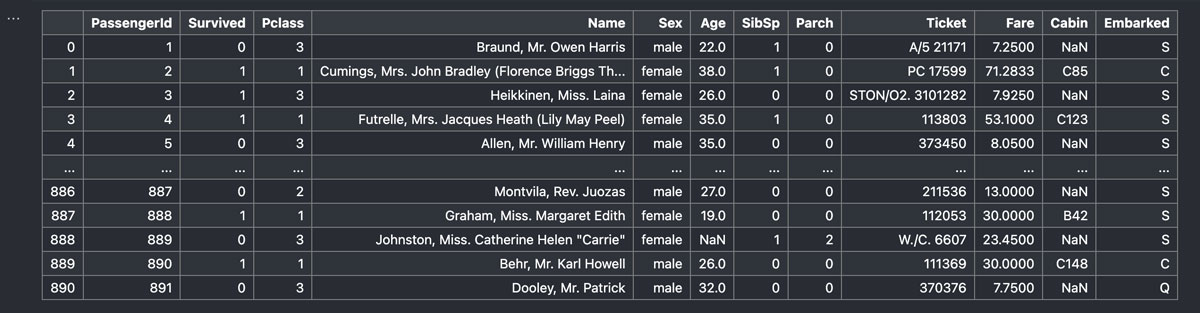
それではこれまでと同じく下の画像のデータフレームを使って具体的な使用例を見ていきましょう。
train_df.loc[1]上述のようにlocは「ラベル」情報を使うのが基本ですが、このように整数を使うこともできます。これは行についての指定となり、「1」というラベルがついた行の情報を抽出することになります。
なぜなら、locもilocも、
データフレーム.loc[①, ②]| ① | 行のインデックス情報 |
| ② | 列のインデックス情報 |
という使い方は同じであり、
loc[1]とすると、最初の情報として指定した整数「1」は自動的に「行についての情報」となるからです。
また整数「1」は「ラベルの名称」(文字列のように)解釈されます、インデックスの順番を示す番号としては扱われません。あくまで「1」という文字を使った行のラベルとして処理されます。
こうして実行結果は、次のようになります。
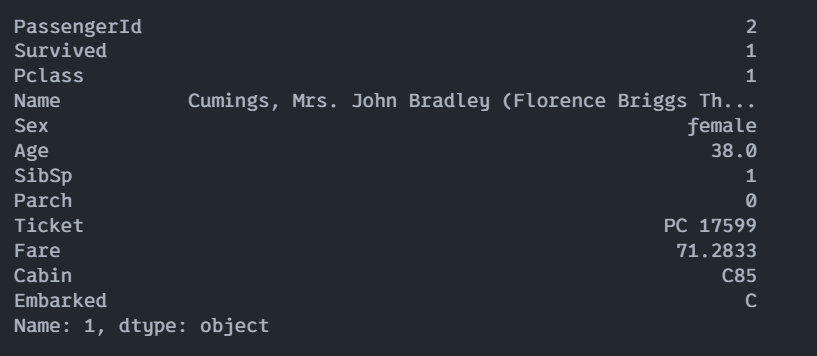
今回指定したラベルの情報はあくまで行についてだけで、列については何もしていないので、行「1」の情報がまとめて表示されます。
train_df.loc[0:2, "PassengerId":"Age"このように行と列のそれぞれにスライス表記を使ってみました。結果は、

このようになります。
ここで重要なのはスライスを使った場合の範囲指定の内容です。
普通Pythonのスライスは、
# 普通はaからb-1までを意味する
a : bこうすると、aから「b-1」までの範囲を指定したことになります。これはiloc[a:b]の場合でも同じです。
しかし上のlocの結果をみてもらうとわかるように、locの場合は、
# locの場合のスライスは、aからbまでを意味する
a : bこのように、aからbまでの範囲を指定したことになります。この点に注意が必要です。
次のように条件を使った指定も可能です。
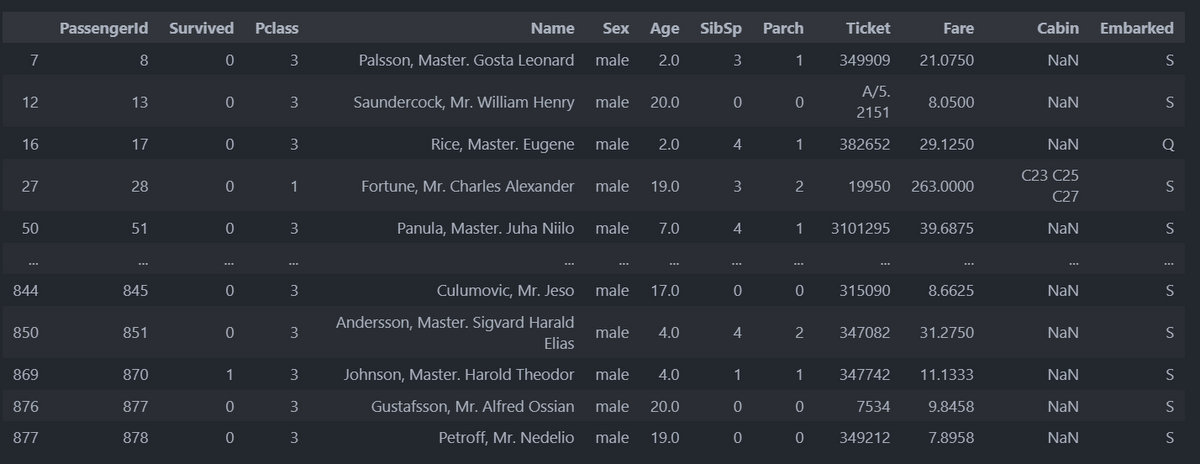
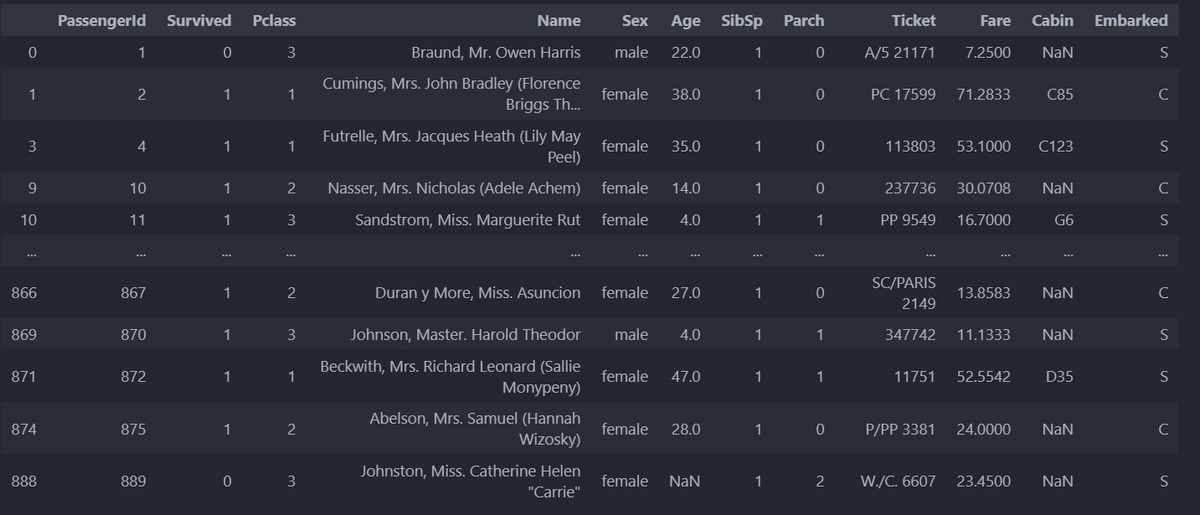
train_df.loc[(train_df["Age"] <= 20.0) & (train_df["Sex"] == "male")]これはAgeが20歳以下でSexがmaleという条件を指定しています。
結果は、
となります。
上述のようにlocはラベル情報だけでなく、ブーリアン型の要素の配列(array)も使うことができます。そこで、ブーリアン型配列を返す関数も使うことができます。
たとえば、ブーリアン型の配列を返すラムダ関数を使ってみます。
train_df.loc[lambda x : x["SibSp"] == 1]この仕組みを大雑把に説明すると、まず変数xには、データフレームtrain_dfが代入されます。そして列ラベルSibSPの値が1という条件を満たすかどうかで0または1のブーリアン型の配列が生成され、それをもとにlocが機能するという仕組みになっています。
結果は、
世界最大級のオンライン学習プラットホームUdemy(ユーデミー)では、Pythonやデータ分析の様々な講座が用意されています。大幅に割引されるセールもよく開催されています。