Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
超初心者にわかりやすくPandasの超基本的な使い方や機能を使い方を解説。平均値、標準偏差などの統計量を取得する方法の解説
今回はPythonを使ったデータサイエンスの第1歩とも言える、超定番ライブラリPandasの基本的な使い方を解説します。PandasとはデータフレームというPandas固有の型のオブジェクト(エクセルの表データのようなイメージです)を作り、上手く処理してくれる便利なライブラリです。使いこなすことは本格的なデータ分析に必須の技能といえるでしょう。
難しそうに感じるかもしれませんが、Pandasは初歩的なPythonの文法を学び終わっただけという段階のレベルでも十分使えるので安心して、そしてどんどん使っていきましょう。
結局、よく使う使い方は毎回同じようなものなので勝手に手が覚えます。習うより慣れろの精神で毎日短時間でも触るようにすればどんどん上達すると思います。
Contents
今回紹介するPandasの属性やメソッドは次の通りです。あくまでPandas全体の機能のごく一部です。
| 機能 (以下データフレームをDFとする) | Pandasのコード (クリックでPandas公式ドキュメントへ) |
|---|---|
| データ読込 | pandas.read_csv |
| DFの行と列の数を確認 | pandas.DataFrame.shape |
| DFのインデックス(行タイトル)確認 | pandas.DataFrame.index |
| DFのコラム(列タイトル)確認 | pandas.DataFrame.columns |
| DFの各列の概要を確認 | pandas.DataFrame.info |
| DFの先頭◯行分だけ表示 | pandas.DataFrame.head |
| DF内部の欠損値を確認 | pandas.DataFrame.isnull |
| DFの各列の要約統計量を確認 | pandas.DataFrame.describe |
| DFの平均値を確認 | pandas.DataFrame.mean |
| DFの中央値を確認 | pandas.DataFrame.median |
| DFの標準偏差を確認 | pandas.DataFrame.std |
今回はよく使うであろうメソッドなどのうち、上記のようなごく一部の超基本的な機能だけの紹介となりますが、これらの基本的なものに慣れておくだけでもかなり今後のPandas学習の一助になると思います。
これらの基本機能の実際の使い方・コード例は以下の「Pandasの基本的な使用例」で紹介していきます。
Pandasの基本的な使い方を学ぶためには統計データが必要です。自分で作ってもいいのですが時間がかかって面倒なだけですし、綺麗に整頓された使いやすいデータで、かつそれなりに本格的な?データを使いたいところです。
そうしたPythonのデータサイエンスの練習として使えるデータはネットでいろいろ公開されています。たとえば有名どころでは日経平均の株価のデータです。
ですが今回は世界的データサイエンスコンペティション(競技大会)として最大級の有名なKaggleで用意されている、タイタニックのデータ(csvファイル)を利用することにします。
まずは次のリンクからKaggleの当該ページへ飛んでください。
Kaggle: Titanic – Machine Learning from Disaster
そのページを少し下へ見ていくと、次の画像のように「Download All」というボタンがあります。
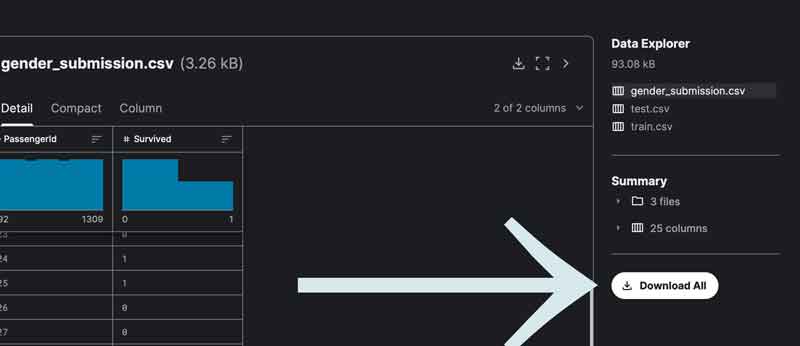
このボタンを押してデータをダウンロードできます。ダウンロード先はPythonのコードを書くファイルと同じフォルダにしておくといろいろ都合が良いと思われます。
なおKaggle用の簡単なDockerコンテナを作る方法は以下の記事で解説しています。Dockerとは何かといった本格的な細かいことは省いた解説ですが、Docker入門としてぜひ試して見てください。
import pandas as pdこのようにしてpandasライブラリをPythonに読み込みます。
「as pd」とすることで、毎回「pandas」と書く必要がなく「pd」と書くだけですみ、省エネ?ができます。
test_df = pd.read_csv('読み込みたいcsvファイルのパス')今回は、test.csvファイルを読み込んだ場合を考えて例えば次のように入力します。
test_df = pd.read_csv('/workspace/.devcontainer/dataset/test.csv')このようにして、右辺で対象となるcsvファイルを読みこみ、Pandas独自のデータフレーム(DataFrame)というオブジェクトを作成し、それを左辺の変数「test_df」に代入しました。
なお変数名で「_df 」とつけているのは、それがデータフレーム」であることを明示したいからです。このへんの命名ルールは人それぞれ、業務現場それぞれでしょうか。
こうしてtest_dfというデータフレームが出来上がったので、ここからはデータフレーム型(以下DF)が有する様々なメソッドなどが使えるようになります。
あとはもう上「今回使うPandasの機能一覧」で紹介したメソッドなどを使っていくだけです。
上でtest_dfというデータフレームオブジェクトをすでに作成しているので、
pandas.DataFrameという部分はすべて、
test_dfで置き換えることができます。
さてそのtest_dfの行がいくつあるのか、そして列がいくつあるのかをそれぞれ確認してみましょう。上「今回使うPandasの機能一覧」で紹介したように、
print(test_df.shape)結果は行と列のタプルで、
(891, 12)print(test_df.index)結果は、
RangeIndex(start=0, stop=891, step=1)このままだとわかりにくいので、例えば次のようしてみました。
index_range = test_df.index
for i in index_range[880:891]:
print(i)こうすると結果は、
880
881
882
883
884print(test_df.columns)結果は、
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')print(test_df.info)結果は、
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
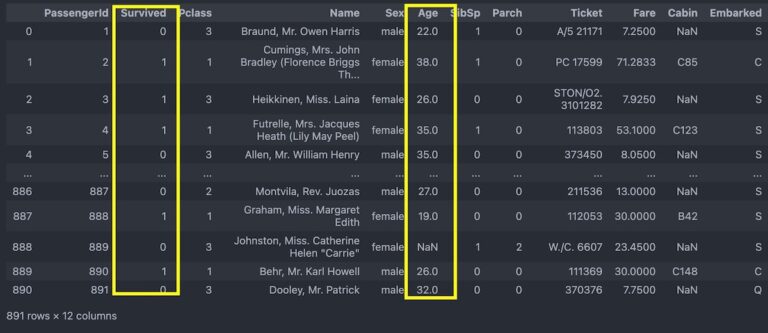
Noneprint(test_df.head(5))結果は、

print(test_df.isnull)結果は、
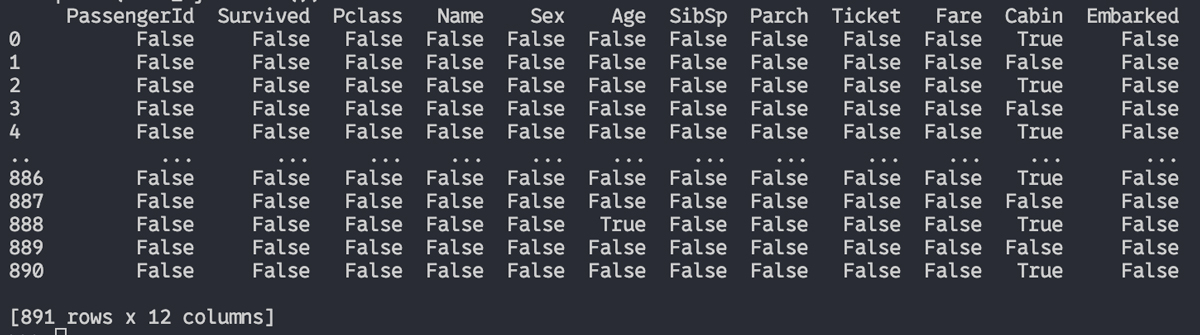
なお、pandas.DataFrame.sumを使って、
print(test_df.isnull().sum()) とすると、各列ごとに欠損値がいくつあったのかその合計を出せます。次のようになります。
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64print(test_df.describe())結果は、

このように、引数に何も設定しないと基本的には上から順番に、
という情報が表示されます。
3つまとめていきましょう。それぞれmean属性、median属性、std属性を使って、
print(test_df.mean)
print(test_df.median)
print(test_df.std)結果は、
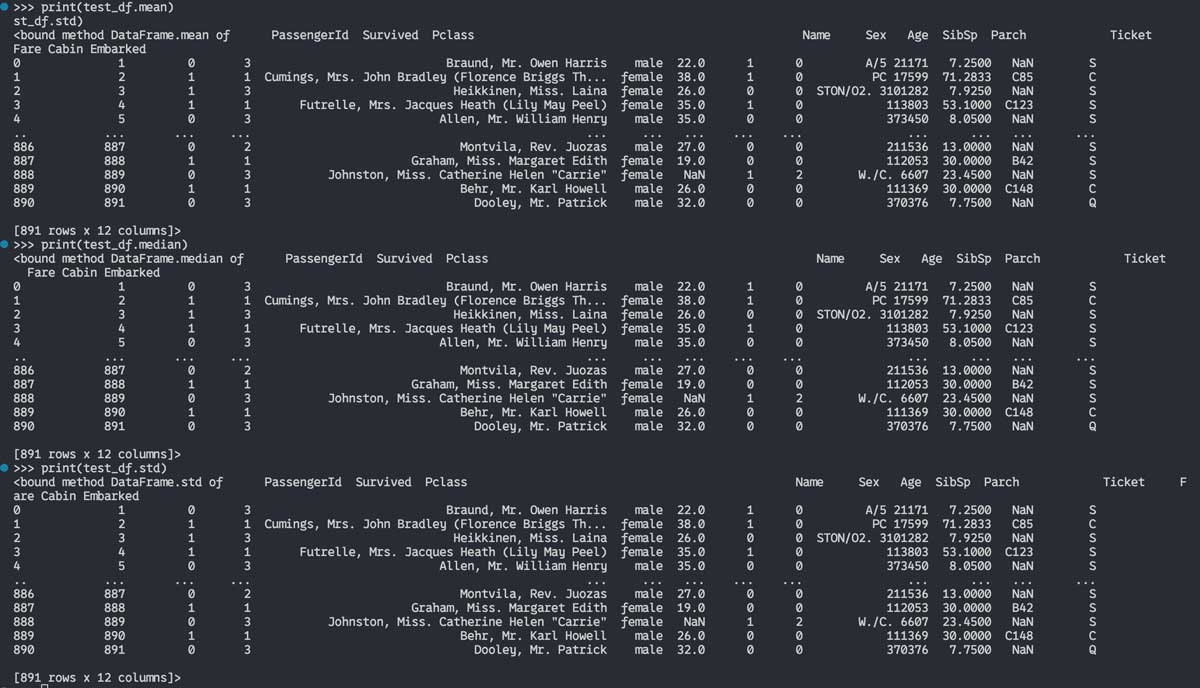
このようになります。
今回の実行結果はすべて文字と数字ばかりで決してグラフィカルに「可視化」したとは言えませんが、なんでもかんでも流行りにのって可視化すればいいというものではなく、逆にグラフィカルでないからこそ数字そのものを客観的に冷静に、そして価値中立的に見られるというメリットもあります。
そしてPandasを使ったデータの可視化という点で便利なおすすめライブラリydata-profilingというものの紹介をこちらの記事で書いていますので続けてご覧ください。
どうだったでしょうか。どれも超基本的な機能ばかりでしたが、やってみれば意外に簡単にデータの概要や平均値などの統計量を確認できることがわかってもらえたでしょうか。
とにかくPythonの初級文法がそれなりに理解できていればPandasはどんどん使えます。そしてそれを基にしてデータ分析とデータサイエンスの世界に入っていけます。ぜひPandasを日常的に使ってみてください。