Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

Pythonで文字列を操作して、HTMLのテーブルタグを出力する自動処理プログラミングを作る方法の解説
以前、Python初心者を対象とした記事「Pythonでテキストファイルを読み込み、自動的にHTMLテーブル(表)を作る方法」という記事を書きましたが、今回も初心者を対象に、実際に自動処理プログラムを作りながら、文字列を操作するためのいくつかのメソッドを解説する記事です。
今回も読み込んだテキストファイルから自動的にHTMLのテーブル(
表)を作り出す簡単なプログラムを作ります。
今回の特徴は、Pythonでテキストファイルから読み込んだ文字列を扱う点です。以下の機能を実装します。
・テキストファイルを読み込む
・文字列の中から、特定の単語(今回はコロン「:」)を見つける
・そのコロン前の文字列とコロン後の文字列という2つのパーツを作る
・英語の単語を日本語の単語に変換する
Contents
今回は次のようなHTMLタグと表が出来上がります。(CSSなどは適用していません)
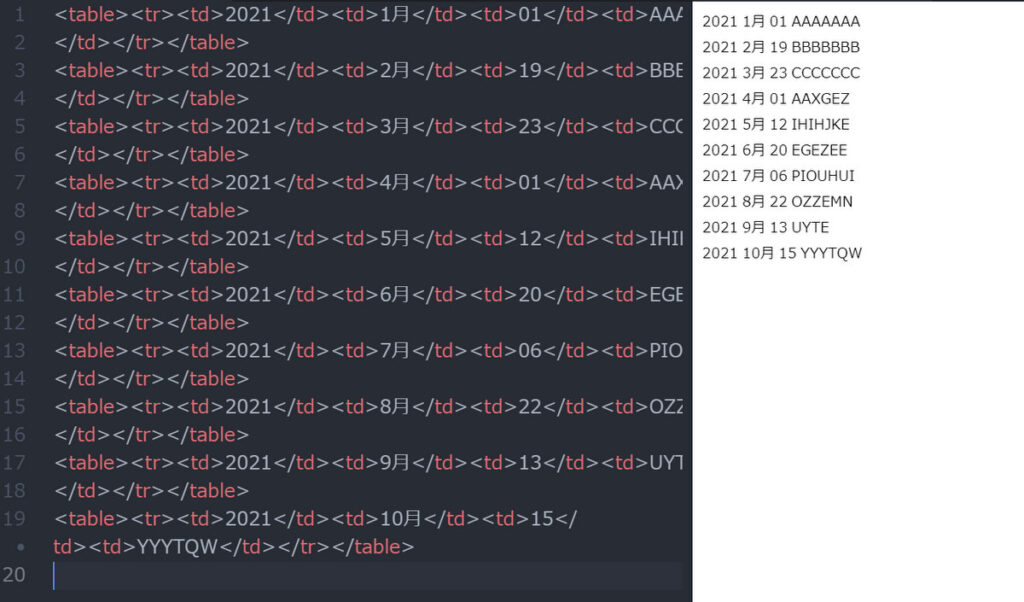
これは私が使っているエディタAtom上の表示で、←側がHTMLタグで、→側がそのHTMLタグを使った表の外観です。
非常に簡単で原始的なものですが、いろいろ手を加えることで応用範囲が広がると思います。
今回はこのようなHTMLタグを自動的に出力するPythonプログラムを作ろうというわけです。
今回読み込むテキストファイルは、仮に次のような中身だとします。
01 January 2021:AAAAAAA
19 February 2021:BBBBBBB
23 March 2021:CCCCCCC
01 April 2021:AAXGEZ
12 May 2021:IHIHJKE
20 June 2021:EGEZEE
06 July 2021:PIOUHUI
22 August 2021:OZZEMN
13 September 2021:UYTE
15 October 2021:YYYTQWようするに、
日 月 年: イベント名このようになっているものです。これがUTF-8エンコード形式で作成されているとします。これは海外で一般的な日時データの書き方となっています。しかし、日本では普通、「年→月→日」という順番でしょう。よって日本風に書き換えた表にするのが目標です。
#1:UTF-8というエンコード形式で作成されたテキストファイルを、読み込み用モード(引数:r)で開く
f=open("テキストファイルのパス", "r", encoding="UTF-8")
#2:テキストファイルから一行ずつ読み込み、ファイル全体を1つのリストとして返す
data=f.readlines()
#3:テキストファイルの行数を把握。forを使って全ての行に同じ処理を施すための準備
length=len(data)
#4:リストの全要素(全行)に同じ処理を繰り返す
for i in range(0,length):
#4-1:コロンを見つける
order_colons=data[i].find(':')
#4-2:コロンの前後で区分する
first_element=data[i][:order_colons]
second_element=data[i][order_colons+1:]
#4-3:コロン前の部分を「半角スペース」によって分割し、新しいリストとして返す
list_first_element=first_element.split()
#4-4:英語の月名を日本語のそれに変換
if list_first_element[1]=="January":
list_first_element[1]="1月"
elif list_first_element[1]=="February":
list_first_element[1]="2月"
elif list_first_element[1]=="March":
list_first_element[1]="3月"
elif list_first_element[1]=="April":
list_first_element[1]="4月"
elif list_first_element[1]=="May":
list_first_element[1]="5月"
elif list_first_element[1]=="June":
list_first_element[1]="6月"
elif list_first_element[1]=="July":
list_first_element[1]="7月"
elif list_first_element[1]=="August":
list_first_element[1]="8月"
elif list_first_element[1]=="September":
list_first_element[1]="9月"
elif list_first_element[1]=="October":
list_first_element[1]="10月"
#4-5:HTMLのタグを出力
print("<table><tr><td>"+list_first_element[2]+"</td><td>"+list_first_element[1]+"</td><td>"+list_first_element[0]+"</td><td>"+second_element+"</td></tr></table>")
f.close()
#2:テキストファイルから一行ずつ読み込み、ファイル全体を1つのリストとして返す
data=f.readlines()まずこれにより、dataという名前のリスト型のオブジェクトを作ります。このオブジェクトは次のような内容となります。
| 要素の順番 | 1 | 2 | 3 | 略 | 10 |
| dataオブジェクトにおける使い方(data[インデックス番号]) | data[0] (インデックス番号は0) | data[1] (インデックス番号は1) | data[2] (インデックス番号は2) | 略 | data[9] (インデックス番号は9) |
| 要素の中身 | 01 January 2021:AAAAAAA (テキストファイルの1行目のデータ) | 19 February 2021:BBBBBBB (テキストファイルの 2行目のデータ) | 23 March 2021:CCCCCCC (テキストファイルの3行目のデータ) | 略 | 15 October 2021:YYYTQW (テキストファイルの10行目のデータ) |
ポイントは「日常生活上における順番」という情報と、「プログラミングの上での順番」という情報がズレている点ですね。Pythonのリスト(または配列)は、最初の順番は「ゼロ」から始まります。上の表での対応をよく見てください。
#4-1:コロンを見つける
order_colons=data[i].find(':')今回は「コロンの前後でパーツを分けたい」ので、まずその基準となる分岐点のコロン(記号「:」)を見つけたいので、文字列から特定の文字を発見するfindメソッドを使っています。
このfindメソッドはその文字が、文頭から何番目にあるのかという情報を返してくれます。
#4-2:コロンの前後で区分する
first_element=data[i][:order_colons]
second_element=data[i][order_colons+1:]この部分ですが、これはPythonの文字列におけるスライスという機能を使っています。
スライスというのは[スタート地点 : ゴール地点]という書き方により、文字列のどこからどこまでを選択するのかを決定できるものです。
ポイントは、ゴール地点の1つ手前まで選択できるという点です。
たとえば、
data[0][1:3]とすると、data[0]の中身である文字列は「01 January 2021:AAAAAAA」でしたので、[1:3]により、
・スタート地点は「1」なので、1文字目の「0」から
・ゴール地点は「3」なので、「3-1」文字目、つまり2文字目「1」まで
という範囲が設定され、その範囲の文字列が選択できます。
よって、
print(data[0][1:3])とすると、「01」という文字列が出力されます。
さて今回は、
#4-2:コロンの前後で区分する
first_element=data[i][:order_colons]
second_element=data[i][order_colons+1:]このような書き方になっていますが、それぞれスタート地点とゴール地点が省略しています。
スライス機能については、
・スタート地点省略→自動的に文字列の最初からという設定
・ゴール地点省略→自動的に文字列の最後までという設定
になります。このような書き方も許されているからです。これにより、
first_element=data[i][:order_colons]左辺のオブジェクトに、data[i]の文字列の1文字目からコロンの手前までの文字列が入ります。同様に、
second_element=data[i][order_colons+1:]左辺のオブジェクトに、data[i]の文字列のコロン後から最後までの文字列が入ります。
このようにして、コロンの前後でパーツを分割することが実現できました。
#4-3:コロン前の部分を「半角スペース」によって分割し、新しいリストとして返す
list_first_element=first_element.split()さて、たとえば、data[0]の前半部分の文字列は「01 January 2021」となるわけですが、次にこれらを「日」「月」「年」という3つのパーツに分割しましょう。
これらは全て「半角スペース」で区切られていますので、半角スペースを基準にして分割しましょう。そこで使うのがsplitメソッドです。
splitメソッドはその引数で指定した文字によって文字列を分割し、同時に各パーツを要素とする新しいリストを作ってくれます。
引数を指定しない場合は自動的に空白文字で分割する仕様になっていますので、今回は何も引数に指定していません。
このsplitにより、新しいリストが作られます。list_first_elementというリストオブジェクトです。たとえば、data[0]の前半部分について言うならば、以下のようになります。
| list_first_element[0] | list_first_element[1] | list_first_element[2] |
| 01 | January | 2021 |
さて、今回のコードはポイントはこんなところです。英語から日本語の変換の部分は特に言う必要はないと思います。もうあまりにも原始的なやり方でそのまますぎるコードなので。
この部分は中級者以上ならば、おそらく正規表現を使ったりreplaceメソッドを使ったクラスを作ったりするのでしょうが、今回のような単純なプログラムならばもう原始的かつ初歩的な書き方で十分でしょう。
今回のコードはあくまでものすごい基本的なものですが、これをどんどん改造してみなさんプログラミング能力を向上させてみてください。